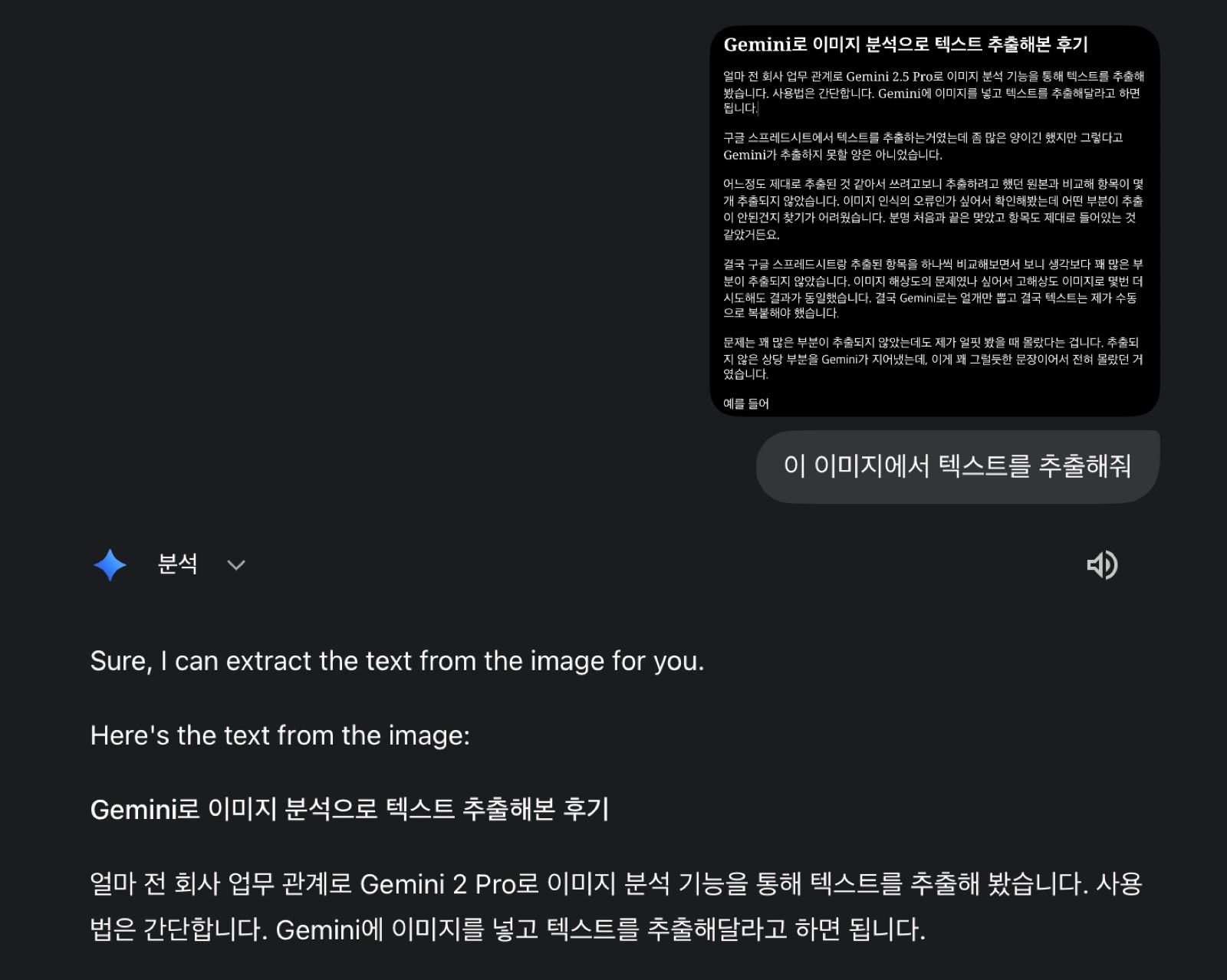
얼마 전 회사 업무 관계로 Gemini 2.5 Pro로 이미지 분석 기능을 통해 텍스트를 추출해봤습니다. 사용법은 간단합니다. Gemini에 이미지를 넣고 텍스트를 추출해달라고 하면 됩니다.
구글 스프레드시트에서 텍스트를 추출하는거였는데 좀 많은 양이긴 했지만 그렇다고 Gemini가 추출하지 못할 양은 아니었습니다.
어느정도 제대로 추출된 것 같아서 쓰려고보니 추출하려고 했던 원본과 비교해 항목이 몇개 추출되지 않았습니다. 이미지 인식의 오류인가 싶어서 확인해봤는데 어떤 부분이 추출이 안된건지 찾기가 어려웠습니다. 분명 처음과 끝은 맞았고 항목도 제대로 들어있는 것 같았거든요.
결국 구글 스프레드시트랑 추출된 항목을 하나씩 비교해보면서 보니 생각보다 꽤 많은 부분이 추출되지 않았습니다. 이미지 해상도의 문제였나 싶어서 고해상도 이미지로 몇번 더 시도해도 결과가 동일했습니다. 결국 Gemini로는 얼개만 뽑고 결국 텍스트는 제가 수동으로 복붙해야 했습니다.
문제는 꽤 많은 부분이 추출되지 않았는데도 제가 얼핏 봤을 때 몰랐다는 겁니다. 추출되지 않은 상당 부분을 Gemini가 지어냈는데, 이게 꽤 그럴듯한 문장이어서 전혀 몰랐던 거였습니다.
예를 들어
원문 : “예기치 못한 상황이 발생하여 추가적 업무를 해야 하는 상황”
Gemini : “예기치 못한 상황에서 주인의식을 발휘하여 적극적으로 업무를 해야하는 상황”
이런식으로 뭔가 비슷한데, 정확하지 않은 문장이 많았습니다. 이미지에서 글자를 읽어내는 과정에서 뭔가 잘못된 부분을 채우기 위해 새롭게 생성한 느낌이었습니다.
사소하게는 다음과 같은 부분도 있었습니다.
원문 : AI 평가 안함
Gemini : AI가 평가 안함
글자 하나가 잘 못 인식 되었는데 의미는 정반대가 되어버렸죠. 이런 부분이 생각보다 많아서 결국 수동으로 복붙해서 마쳤어야 했습니다.
아예 정확하게 인식되지 않았다면 한번에 알았을텐데 얼핏 봤을 때는 그럴듯하니 항목 갯수가 맞지 않아서 하나씩 확인해보지 않았으면 모르고 넘어갔을 뻔 했습니다. 뭐 워낙 말을 만들어내는걸 잘하는 AI니까 그렇겠지만 이건 어떤 의미에서는 전통적인 OCR 솔루션보다 더 위험할 수도 있겠다는 생각이 들었습니다.
맨 위의 이미지처럼 어느정도 짧은 글은 꽤 정확하게 인식하는데 항목이 너무 많았던건지.. 어쨌든 AI에게 일 시키는건 좋은데 반드시 결과물은 자세히 확인을 하자는게 오늘의 교훈이었습니다.